从输入 URL 到页面展示到底发生了什么?
在浏览器地址栏输入 URL 到页面展示,背后会串起 DNS、TCP、TLS、HTTP、ARP、数据封装与浏览器渲染等多个环节。
这道题经常被用来考察计网整体理解,因为它能把应用层、传输层、网络层和链路层的知识点都串起来。只背单个协议容易断片,按访问网页的全过程走一遍,会清楚很多。
这篇文章主要回答几个问题:
- 输入 URL 后,浏览器会先做哪些本地处理?
- DNS 解析域名的过程是怎样的?
- TCP 连接如何建立?如果用了 HTTPS,TLS 握手又做了什么?
- HTTP 请求和响应的交互流程是什么?
- 数据包从主机到服务器,经过了哪些层的封装和转发?
- 浏览器拿到 HTML 后,如何继续加载 CSS、JS、图片等资源并渲染页面?
- 页面加载完成后,连接会如何复用或关闭?
总的来说,网络通信模型可以用下图来表示。访问网页的过程,就是数据从应用层逐层向下封装,经物理网络传输到对端,再逐层向上解封装的过程。
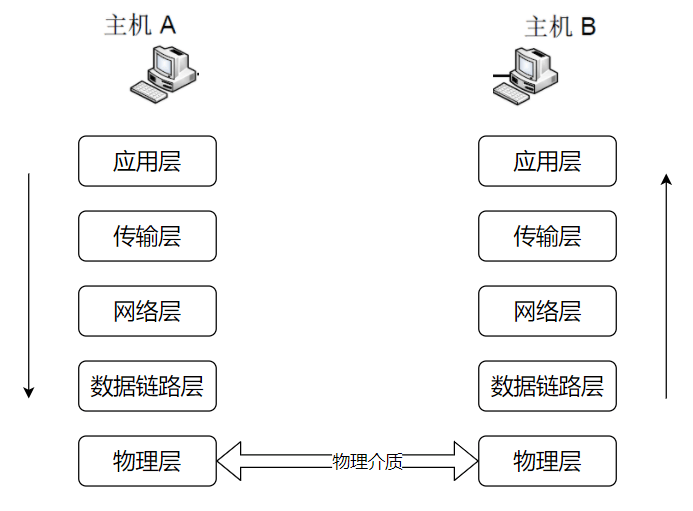
开始之前,先简单过一遍完整流程:
- 浏览器解析 URL 并检查缓存:浏览器解析 URL 的各组成部分,并检查 HTTP 缓存(强缓存、协商缓存)是否已有该资源的有效副本。
- DNS 解析:浏览器通过 DNS 协议,获取域名对应的 IP 地址。
- 建立 TCP 连接:浏览器根据 IP 地址和端口号,向目标服务器发起 TCP 三次握手,建立可靠传输通道。
- TLS 握手(HTTPS):如果使用 HTTPS,在 TCP 连接建立后还要进行 TLS 握手,协商加密密钥并验证服务器身份。
- 发送 HTTP 请求:浏览器在连接上向服务器发送 HTTP 请求报文,请求获取网页内容。
- 服务器处理并返回响应:服务器收到请求后处理并返回 HTTP 响应报文。
- 浏览器解析与渲染:浏览器解析 HTML、CSS,执行 JavaScript,并加载页面中引用的其他资源(图片、字体等)。
- 连接管理:页面加载完成后,连接根据 keep-alive 策略复用或关闭。
下面按这个流程逐一展开。
第一步:解析 URL 与检查缓存
打开浏览器,在地址栏输入 URL 并回车。浏览器做的第一件事不是发请求,而是解析 URL 并检查是否可以直接使用本地缓存。
URL 是什么
URL(Uniform Resource Locator,统一资源定位符)是互联网上资源的唯一地址。网络上的每个可访问资源都对应一个 URL,理论上文件和 URL 一一对应。实际上也有例外,比如重定向或 CDN 场景下,多个 URL 可能指向同一份资源。
URL 的组成结构

一个完整的 URL 由以下几部分组成:
- 协议(Scheme):URL 的前缀表示采用的协议,最常见的是
http和https,也有文件传输的ftp:等。 - 域名(Host):访问目标的通用名,也可以直接使用 IP 地址。域名本质上是 IP 地址的可读版本。
- 端口(Port):紧跟域名后面,用冒号隔开。HTTP 默认 80,HTTPS 默认 443,如果使用默认端口可以省略。
- 资源路径(Path):从第一个
/开始,表示服务器上的资源位置。早期设计中路径对应服务器上的物理文件,现在通常是后端路由映射的虚拟路径。 - 查询参数(Query):
?之后的部分,采用key=value键值对形式,多个参数用&隔开。服务器解析请求时会提取这些参数。 - 锚点(Fragment):
#之后的部分,用于定位到页面内的某个位置。锚点不会作为请求的一部分发送给服务端,仅由浏览器本地处理。
浏览器缓存检查
解析完 URL 之后,浏览器会先检查 HTTP 缓存,看是否已经有该资源的有效副本:
- 强缓存:检查
Cache-Control(如max-age)或Expires头,判断缓存是否仍在有效期内。如果有效,直接使用缓存,跳过后续所有网络请求。 - 协商缓存:强缓存未命中时,浏览器向服务器发送验证请求(携带
If-Modified-Since或If-None-Match),服务器判断资源是否变化。如果未变化,返回304 Not Modified,浏览器继续使用本地缓存;如果已变化,返回200 OK和新资源。
HTTP 缓存命中时,整个访问过程在此结束,无需发起网络请求。
域名解析准备
如果 HTTP 缓存未命中,浏览器需要向服务器发起网络请求,首先要拿到域名对应的 IP 地址。在正式发起 DNS 查询之前,浏览器还会依次检查:
- 浏览器 DNS 缓存:浏览器自身维护了一份 DNS 缓存,先看有没有该域名的记录。
- 操作系统 DNS 缓存:浏览器缓存未命中时,查询操作系统的 DNS 缓存。
- hosts 文件:操作系统会检查本地
hosts文件,看是否有域名到 IP 地址的直接映射。如果有,直接使用该 IP 地址,跳过 DNS 解析。
如果以上都没有命中,浏览器就需要发起完整的 DNS 查询。
第二步:DNS 解析
DNS(Domain Name System,域名系统)要解决的是域名和 IP 地址的映射问题。域名只是便于人类记忆的名字,网络通信真正需要的是 IP 地址。
DNS 解析过程
浏览器拿到域名后,DNS 解析通常按以下步骤进行:
- 浏览器 DNS 缓存:浏览器自身维护了一份 DNS 缓存,先检查缓存中是否有该域名的记录且未过期。
- 操作系统 DNS 缓存:浏览器缓存未命中时,向操作系统发起 DNS 查询请求。操作系统也有自己的 DNS 缓存。
- 本地 DNS 服务器:操作系统配置的本地 DNS 服务器(通常由 ISP 提供,或使用公共 DNS 如
8.8.8.8、114.114.114.114)。本地 DNS 服务器如果有缓存且未过期,直接返回结果。 - 递归/迭代查询:本地 DNS 服务器缓存未命中时,它会代替客户端发起迭代查询——先问根 DNS 服务器,再问顶级域 DNS 服务器(如
.com),最后问权威 DNS 服务器,逐级获取目标 IP 地址。 - 返回结果并缓存:本地 DNS 服务器拿到最终结果后返回给客户端,同时在本地缓存一份,供后续查询使用。
下图展示了一个典型的 DNS 迭代查询过程:
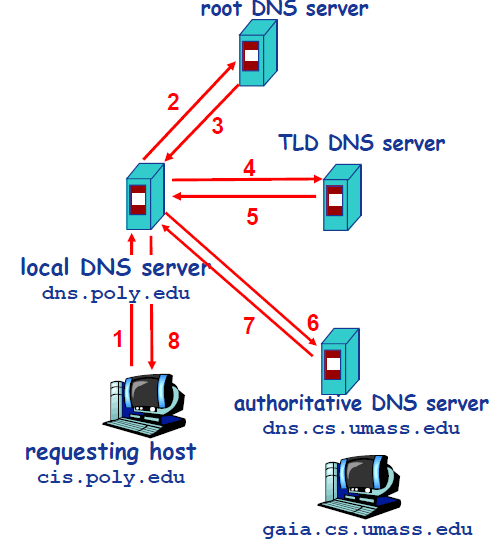
实际场景中,本地 DNS 服务器通常已经缓存了大量 TLD 服务器地址,多数查询不需要从根服务器开始,跳过根服务器直接查 TLD 的情况非常普遍。
关于 DNS 的更多细节(DNS 服务器层级、递归/迭代查询的区别、DNS 记录类型、为什么通常用 UDP 等),可以参考 DNS 域名系统详解(应用层) 这篇文章。
第三步:建立 TCP 连接
拿到目标服务器的 IP 地址后,浏览器需要与服务器建立一个可靠的传输通道。HTTP 基于 TCP 协议,所以在发送 HTTP 请求之前必须先完成 TCP 三次握手。
TCP 三次握手
TCP 三次握手的目的是同步双方的初始序列号,并确认双方的收发路径是可用的。
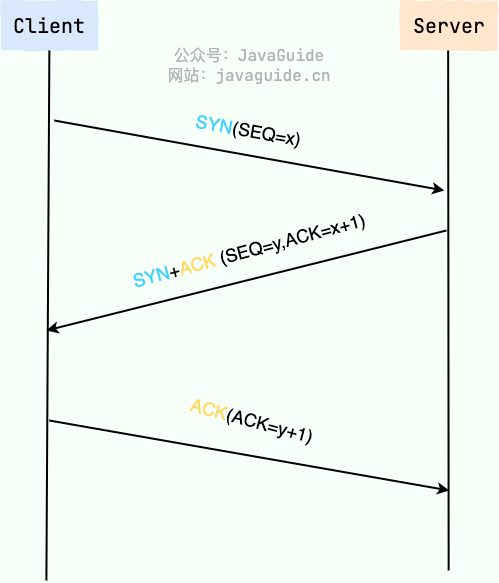
- 第一次握手(SYN):客户端发送 SYN 报文段,携带自己的初始序列号
seq=x,进入SYN_SENT状态。 - 第二次握手(SYN+ACK):服务端收到后回复 SYN+ACK,携带自己的初始序列号
seq=y,确认号ack=x+1,进入SYN_RCVD状态。 - 第三次握手(ACK):客户端收到后发送 ACK,确认号
ack=y+1,双方进入ESTABLISHED状态,连接建立完成。
三次握手的设计不是为了「多走一次」,而是让双方都能确认:对方能收到自己的数据,自己也能收到对方的数据。两次握手做不到这一点——服务端在第二次握手后,还不知道客户端是否收到了自己的 SYN+ACK。
关于三次握手的详细分析、半连接队列/全连接队列、SYN Flood 防护等内容,可以参考 TCP 三次握手和四次挥手(传输层)。
如果是 HTTPS:TLS 握手
如果 URL 的协议是 HTTPS,TCP 连接建立之后还要进行 TLS 握手。TLS 的核心目标是三个:加密(防窃听)、认证(防冒充)、完整性校验(防篡改)。
TLS 握手大致流程(以 TLS 1.2 RSA 密钥交换为例):
- Client Hello:客户端发送支持的 TLS 版本、加密套件列表和一个随机数。
- Server Hello:服务端从中选择一个加密套件,返回自己的证书、另一个随机数。
- 密钥交换:客户端验证服务端证书的合法性(通过 CA 签名验证),然后生成预主密钥(Pre-Master Secret),用服务端公钥加密后发送给服务端。双方根据预主密钥和之前交换的两个随机数,计算出对称加密的会话密钥。
- 完成:双方用会话密钥加密通信,握手结束。
需要注意的是,上述流程描述的是 TLS 1.2 中基于 RSA 的密钥交换方式。现代 HTTPS 主流采用的是 ECDHE 密钥交换(TLS 1.2 和 TLS 1.3 均支持),密钥材料不是直接用公钥加密传输的,而是通过椭圆曲线 Diffie-Hellman 交换各自生成,并且具备前向安全性(Forward Secrecy)——即使服务端私钥泄露,历史通信也不会被解密。TLS 1.3 进一步简化了握手流程,将往返次数从 2-RTT 减少到 1-RTT,并移除了 RSA 静态密钥交换等不安全的密码套件。
TLS 握手完成后,后续的 HTTP 请求和响应都会使用协商好的对称密钥进行加密传输。HTTPS 的安全性来自 TLS 层,而不是 HTTP 协议本身的改变。
关于 TLS 的加密原理(非对称加密、对称加密、数字签名、CA 证书)的详细分析,可以参考 HTTP vs HTTPS(应用层)。关于 RSA 和 ECDHE 两种密钥交换方式的区别,可以参考 HTTPS RSA vs ECDHE 握手过程。
第四步:发送 HTTP 请求
TCP 连接(以及可能的 TLS 通道)建立好之后,浏览器就可以发送 HTTP 请求了。
HTTP 请求报文结构
一个典型的 HTTP/1.1 请求报文如下:
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
Accept: text/html,application/xhtml+xml
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: keep-alive
Cookie: session_id=abc123
各部分含义:
- 请求行:
GET /index.html HTTP/1.1—— 请求方法(GET)、资源路径(/index.html)、协议版本(HTTP/1.1)。 - Host 头:指定目标主机名。这是 HTTP/1.1 的强制要求,因为同一台服务器(同一个 IP)可能通过虚拟主机托管多个网站。
- 其他请求头:
User-Agent(客户端信息)、Accept(可接受的响应类型)、Accept-Encoding(支持的压缩方式)、Cookie(携带的状态信息)等。
服务器处理请求
服务器收到请求后,经过一系列处理生成响应:
- 接收请求:Web 服务器(如 Nginx、Tomcat)接收并解析 HTTP 请求报文。
- 路由分发:根据 URL 路径将请求路由到对应的后端处理逻辑(Controller、Servlet 等)。
- 业务处理:执行具体的业务逻辑,可能涉及数据库查询、缓存读取、调用其他服务等。
- 构建响应:将处理结果封装成 HTTP 响应报文。
HTTP 响应报文结构
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Encoding: gzip
Content-Length: 1256
Cache-Control: max-age=3600
Set-Cookie: session_id=xyz789; Path=/
<!DOCTYPE html>
<html>
...
</html>
各部分含义:
- 状态行:
HTTP/1.1 200 OK—— 协议版本、状态码(200)、状态描述。 - 响应头:
Content-Type(响应体类型)、Content-Encoding(压缩方式)、Cache-Control(缓存策略)、Set-Cookie(设置 Cookie)等。 - 响应体:请求的实际内容,如 HTML 文档、JSON 数据、图片二进制数据等。
常见的状态码:
| 状态码 | 类别 | 常见示例 |
|---|---|---|
| 2xx | 成功 | 200 OK、206 Partial Content |
| 3xx | 重定向 | 301 永久重定向、302 临时重定向、304 未修改 |
| 4xx | 客户端错误 | 400 Bad Request、403 Forbidden、404 Not Found |
| 5xx | 服务端错误 | 500 Internal Server Error、502 Bad Gateway |
关于 HTTP 常见状态码的详细总结,可以参考 HTTP 常见状态码总结(应用层)。
第五步:数据包的封装与转发
HTTP 请求从浏览器发出后,数据并不是直接「飞」到服务器的。它需要经过协议栈的逐层封装,在物理网络上一跳一跳地转发到目的地。
数据封装过程
应用层的 HTTP 报文,经过传输层、网络层、链路层的逐层封装,最终变成能在物理介质上传输的比特流:
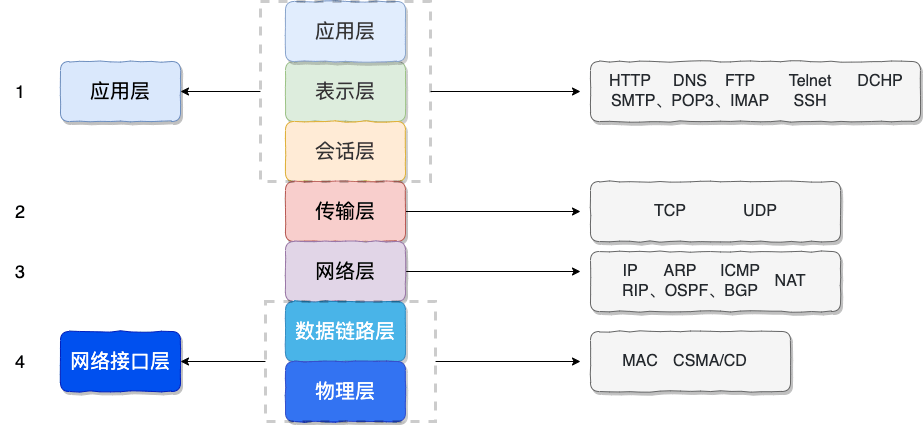
每一层只关心自己要添加的头部信息,并使用下层提供的服务来传输数据:
- 传输层(TCP):添加源端口和目的端口,用序列号和确认号保证可靠传输。
- 网络层(IP):添加源 IP 和目的 IP,负责寻址和路由,决定数据包从源到目的经过的路径。
- 链路层:添加源 MAC 和目的 MAC 地址,负责在相邻节点之间传输数据帧。
网络层的路由转发
数据包从源主机到目的主机,通常需要经过多个路由器中转。网络层的核心功能就是路由与转发:
- 路由:确定分组从源到目的经过的路径(由路由协议如 OSPF、BGP 等计算)。
- 转发:将分组从路由器的输入端口转移到合适的输出端口。
每个路由器维护一张路由表,根据目的 IP 地址查表决定下一跳。数据包在网络中就像快递包裹,每一站只看「下一站发到哪里」,不用关心全程路径。
ARP 协议:从 IP 地址到 MAC 地址
数据帧在链路层传输时,需要知道下一跳设备的 MAC 地址,而不能只用 IP 地址。ARP(Address Resolution Protocol,地址解析协议)就是解决「已知 IP 地址,如何获取对应 MAC 地址」的问题。
ARP 的工作方式是广播问询、单播响应:
- 主机先查本地 ARP 缓存表,看是否已有目标 IP 对应的 MAC 地址。
- 缓存未命中时,在局域网内广播一个 ARP 请求:「谁的 IP 是 xxx.xxx.xxx.xxx?请告诉我你的 MAC地址。」
- 目标设备(或路由器接口)收到后,以单播方式回复自己的 MAC 地址。
- 请求方收到响应后,将 IP-MAC 映射存入 ARP 缓存表,后续通信直接使用。
如果目标主机不在同一子网,主机不需要知道最终目标的 MAC 地址,只需要知道本地网关(路由器)的 MAC 地址即可。数据包先发给网关,网关再逐跳转发到目标网络。
关于 ARP 的详细工作原理(同子网/跨子网寻址、ARP 表、常见攻击),可以参考 ARP 协议详解(网络层)。
网络地址转换(NAT)
在大多数家庭和企业网络中,内网主机使用的是私有 IP 地址(如 192.168.x.x),不能直接在公网上路由。NAT(Network Address Translation)协议负责在内网和公网之间转换 IP 地址。
当内网主机发送数据包到公网时,NAT 设备(通常是路由器)会将源 IP 地址从私有地址替换为公网地址,并记录端口映射关系。响应数据包返回时,NAT 再根据映射表把目的地址转换回内网主机的私有地址。
第六步:浏览器解析与渲染
服务器返回 HTML 响应后,浏览器的工作才真正开始。浏览器需要解析 HTML、构建 DOM 树、加载子资源、计算样式、布局并最终渲染到屏幕上。
HTML 解析与 DOM 构建
浏览器拿到 HTML 文档后,从上到下逐行解析:
- 构建 DOM 树:解析 HTML 标签,生成文档对象模型(DOM)树,表示页面的结构。
- 构建 CSSOM 树:遇到
<link>引用的 CSS 文件或<style>标签时,下载并解析 CSS,生成 CSS 对象模型(CSSOM)树,表示页面的样式规则。 - 构建渲染树:将 DOM 树和 CSSOM 树合并,生成渲染树。渲染树只包含需要显示的节点及其样式信息(
display: none的元素不会出现在渲染树中)。 - 布局(Layout):计算渲染树中每个节点的位置和大小。
- 绘制(Paint):将布局后的渲染树转换为屏幕上的像素。
- 合成(Composite):将不同图层合成最终画面显示在屏幕上。
子资源加载
HTML 文档通常会引用大量外部资源:
- CSS 文件(
<link rel="stylesheet">):普通阻塞样式表会阻塞渲染,浏览器通常会等 CSS 加载并解析完成后才进行布局和绘制,因为 CSS 可能改变元素的布局。通过media属性、动态加载或preload等方式可以改变这一行为。 - JavaScript 文件(
<script>):默认会阻塞 HTML 解析,因为 JavaScript 可能修改 DOM。可以通过async或defer属性改变加载行为。 - 图片、字体等:不会阻塞 HTML 解析,但需要在加载完成后才能显示。
这些子资源的加载会触发额外的 HTTP 请求。如果使用 HTTP/1.1,浏览器通常会对同一域名维护最多 6 个并发 TCP 连接来并行下载资源。HTTP/2 的多路复用机制则允许在同一个 TCP 连接上并行传输多个资源。
JavaScript 执行
JavaScript 的执行会阻塞 HTML 解析。浏览器遇到 <script> 标签时,会暂停 DOM 构建,先下载并执行脚本。如果脚本中有 DOM 操作,可能会触发 DOM 重构和页面重排(Reflow)或重绘(Repaint)。
现代前端开发中常用的优化手段包括:
- 将
<script>放在<body>底部或使用defer属性,避免阻塞 DOM 解析。 - 使用
async属性异步加载不影响 DOM 的脚本。 - 通过 CDN 加速静态资源加载。
- 利用浏览器缓存减少重复请求。
第七步:连接管理
页面和资源加载完成后,TCP 连接不会立刻断开,如何管理连接取决于 HTTP 版本和配置。
HTTP/1.0 短连接
HTTP/1.0 默认使用短连接:每次请求-响应完成后就关闭 TCP 连接。如果页面引用了 10 个外部资源,浏览器需要建立 10 次独立的 TCP 连接,每次都要经历三次握手和四次挥手,大量时间花在连接的建立和释放上。
HTTP/1.1 长连接(Keep-Alive)
HTTP/1.1 默认使用长连接(Connection: keep-alive)。一个 TCP 连接建立后可以连续发送多个请求和接收多个响应,不需要每次都重新握手。这样页面中的 CSS、JS、图片等子资源可以复用同一个 TCP 连接来加载。
长连接不是永久的。服务器通常配置了空闲超时时间(如 Apache 的 KeepAliveTimeout),如果在超时时间内没有新的请求,服务器才会主动关闭连接。
HTTP/2 多路复用
HTTP/2 在长连接的基础上引入了多路复用。同一个 TCP 连接上可以同时传输多个请求和响应,数据被拆分成更小的帧并通过流(Stream)标识来区分归属。这解决了 HTTP/1.1 在应用层面的队头阻塞问题——前面的慢请求不会挡住后面的请求。需要注意的是,HTTP/2 仍然基于 TCP,当 TCP 层发生丢包时,同一连接上的所有流都会受影响(TCP 层队头阻塞)。HTTP/3 基于 QUIC 协议(UDP),才进一步缓解了这个问题。
连接关闭
当连接确实需要关闭时(主动关闭方发起):
- 主动关闭方发送 FIN,表示自己没有数据要发了。
- 被动关闭方回复 ACK,进入
CLOSE_WAIT状态,但还可以继续发送剩余数据。 - 被动关闭方数据发完后也发送 FIN。
- 主动关闭方回复最终 ACK,进入
TIME_WAIT状态,等待 2MSL 后彻底关闭。
TIME_WAIT 状态的存在是为了确保最后的 ACK 能到达对端,同时让网络中残留的旧报文消散,避免干扰后续新连接。
关于 TCP 四次挥手、TIME_WAIT 的影响、CLOSE_WAIT 堆积排查等内容,可以参考 TCP 三次握手和四次挥手(传输层)。
完整流程总结
把上面的步骤串起来,完整的访问流程可以概括为:
- 输入 URL → 浏览器解析 URL 各部分,检查 HTTP 缓存;如需网络请求,再检查 hosts 文件。
- DNS 解析 → 依次查询浏览器缓存、操作系统缓存、本地 DNS 服务器,必要时经根 → TLD → 权威服务器迭代查询,获取目标 IP 地址。
- TCP 三次握手 → 浏览器与服务器建立可靠传输通道。
- TLS 握手(HTTPS) → 协商加密密钥、验证证书,建立安全通道。
- HTTP 请求与响应 → 浏览器发送请求,服务器处理并返回 HTML 响应。
- 数据封装与转发 → 请求报文经 TCP → IP → 链路层逐层封装,通过路由器、交换机等中间设备一跳一跳转发到服务器;响应沿反方向回到浏览器。
- 浏览器渲染 → 解析 HTML 构建 DOM 树,加载 CSS/JS/图片等子资源,构建渲染树,布局并绘制页面。
- 连接管理 → 根据 HTTP 版本和配置复用或关闭 TCP 连接。
访问一个网页看似简单,实际上串起了计算机网络几乎所有的核心协议。按这个流程去理解,DNS、TCP、TLS、HTTP、IP、ARP 这些协议就不再是孤立的知识点,而是一条完整链路上的不同环节。
参考
- 《计算机网络(第 7 版)》
- 《图解 HTTP》
- What really happens when you navigate to a URL
- How browsers work